Explainable Grounded Segment Anything
An image segmentation pipeline that leverages Grounding DINO and Segment Anything Model (SAM) for text-guided image segmentation. It uses Grounding DINO as the first step to generate bounding boxes around entities in the image based on a user-provided text prompt. These bounding boxes are then passed into the Segment Anything Model (SAM), which performs finer segmentation on the image. Additionally, the pipeline features an explainable interface that uses attention maps to provide insights into the model’s decision-making process.
Project Report: Report
Getting Started
Follow the steps below to run this project locally for development and testing.
Prerequisites
Ensure the following libraries and frameworks are installed:
- PyTorch GPU Version
- GroundingDINO
- Segment Anything
Installation
- Clone the repository:
git clone https://github.com/Vamsi995/Explainable-Grounded-Segment-Anything.git
cd Explainable-Grounded-Segment-Anything
- Install Dependencies:
pip install -r requirements.txt - Grounding DINO Setup
git clone https://github.com/IDEA-Research/GroundingDINO.git
git checkout -q 57535c5a79791cb76e36fdb64975271354f10251
pip install --upgrade pip setuptools
pip install build wheel
pip install -e .
- Segment Anything Model Setup
pip install 'git+https://github.com/facebookresearch/segment-anything.git' - Download GroundingDINO & Segment Anything Model Weights
cd weights
!wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
!wget -q https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
Usage
- Run the driver script:
python segment.py
Pipeline Flow
- Grounding DINO: The first step in the pipeline, where bounding boxes are generated based on the input text prompt. Grounding DINO identifies entities in the image that correspond to the prompt.
- Segment Anything Model (SAM): Once the bounding boxes are identified, SAM segments the image more precisely within these regions.
- Explainable Interface: To offer interpretability, the pipeline extracts attention maps from the last attention layer of the Vision Transformer (ViT) block used in SAM. These maps are then overlayed on the original image as heatmaps to explain what the model is focusing on during segmentation.
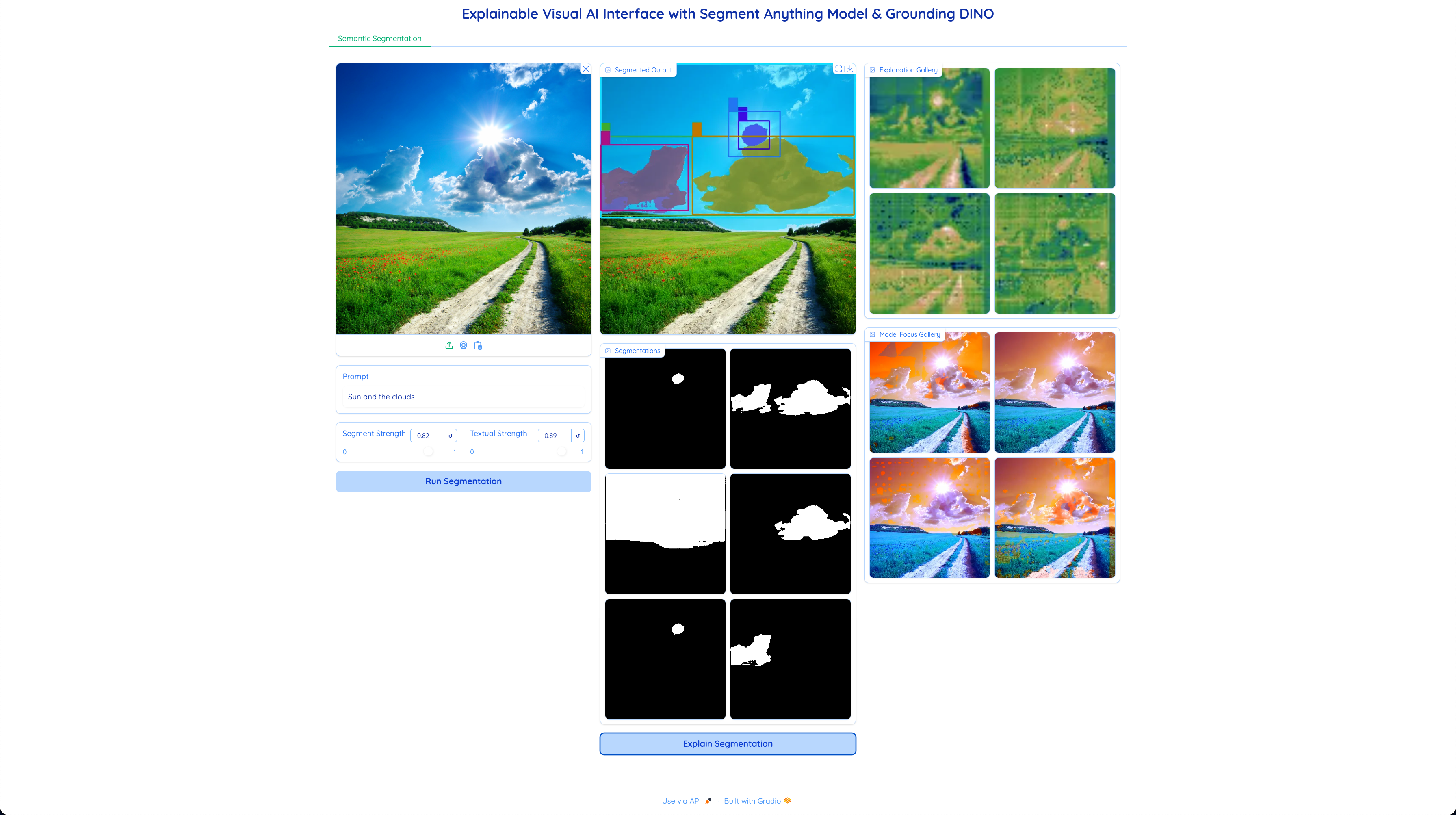
Gradio Interface
The interface is simple, lightweight, and divided into three panels:
Panel 1: Input
- Image Upload: Upload the image to be segmented.
- Text Prompt: Input the text that specifies the entities to be segmented.
- Segmentation Strength: Adjust the strength of segmentation to fine-tune the results.
- Text Output: Choose whether to display the prompt text on the segmented output.
- Run Segmentation: After inputting the image and prompt, hit the Run Segmentation button to initiate the segmentation process.
Panel 2: Segmentation Output
- Segmented Image: Displays the segmented image after the SAM model processes the input.
- Segmentation Masks: Provides the segmentation masks corresponding to the regions identified in the image.
Panel 3: Explanation
- Explain Segmentation: By clicking the Explain Segmentation button, attention maps are generated by hooking into the last attention layer of the SAM model.
- Activation Maps: The attention maps are overlaid as heatmaps on the original image to visualize what the model is focusing on. The areas with the highest intensity represent the model’s primary focus during segmentation.